Example: Nonlinear energy functional minimization
In this example we solve the following nonlinear minimization problem
Find such that
Here the energy functional $\Pi(u)$ has the form
where
Necessary condition (Euler-Lagrange condition)
Let $\delta_u \Pi(u, \hat{u})$ denote the first variation of $\Pi(u)$ in the direction $\hat{u}$, i.e.
The necessary condition is that the first variation of $\Pi(u)$ equals to 0 for all directions $\hat{u}$:
.
Weak form:
To obtain the weak form of the above necessary condition, we first expand the term $\Pi(u + \varepsilon \hat{u})$ as
After some simplification, we obtain
By neglecting the $\mathcal{O}(\epsilon)$ terms, we write the weak form of the necessary conditions as
Find such that
Strong form:
To obtain the strong form, we invoke Green’s first identity and write
Since $\hat{u}$ is arbitrary in $\Omega$ and $\hat{u} = 0$ on $\partial \Omega$, the strong form of the non-linear boundary problem reads
Infinite-dimensional Newton’s Method
Consider the expansion of the first variation $\delta_u \Pi(u, \hat{u})$ about $u$ in a direction $\tilde{u}$
where
The infinite-dimensional Newton’s method reads
Given the current solution $u_k$, find $\tilde{u} \in H^1_0$ such that
Update the solution using the Newton direction $\tilde{u}$
Hessian
To derive the weak form of the Hessian, we first expand the term $\delta_u \Pi(u +\varepsilon \tilde{u},\hat{u})$ as
Then, after some simplification, we obtain
Weak form of Newton step:
Given , find $\tilde{u} \in H^1_0$ such that
The solution is then updated using the Newton direction $\tilde{u}$
Here $\alpha$ denotes a relaxation parameter (back-tracking/line-search) used to achieve global convergence of the Newton method.
Strong form of the Newton step
1. Load modules
To start we load the following modules:
-
dolfin: the python/C++ interface to FEniCS
-
math: the python module for mathematical functions
-
numpy: a python package for linear algebra
-
matplotlib: a python package used for plotting the results
import matplotlib.pyplot as plt
%matplotlib inline
from dolfin import *
import math
import numpy as np
import logging
logging.getLogger('FFC').setLevel(logging.WARNING)
logging.getLogger('UFL').setLevel(logging.WARNING)
set_log_active(False)
2. Define the mesh and finite element spaces
We construct a triangulation (mesh) $\mathcal{T}_h$ of the computational domain $\Omega := [0, 1]^2$ with nx elements in the x-axis direction and ny elements in the y-axis direction.
On the mesh $\mathcal{T}_h$, we then define the finite element space $V_h \subset H^1(\Omega)$ consisting of globally continuous piecewise linear functions and we create a function $u \in V_h$.
By denoting by the finite element basis for the space $V_h$ we have
where ${\rm u}_i$ represents the coefficients in the finite element expansion of $u$.
Finally we define two special types of functions: the TestFunction $\hat{u}$ and the TrialFunction $\tilde{u}$. These special types of functions are used by FEniCS to generate the finite element vectors and matrices which stem from the first and second variations of the energy functional $\Pi$.
nx = 32
ny = 32
mesh = UnitSquareMesh(nx,ny)
Vh = FunctionSpace(mesh, "CG", 1)
uh = Function(Vh)
u_hat = TestFunction(Vh)
u_tilde = TrialFunction(Vh)
plot(mesh)
print "dim(Vh) = ", Vh.dim()
dim(Vh) = 1089

3. Define the energy functional
We now define the energy functional
The parameters $k_1$, $k_2$ and the forcing term $f$ are defined in FEniCS using the keyword Constant. To define coefficients that are space dependent one should use the keyword Expression.
The Dirichlet boundary condition
is imposed using the DirichletBC class.
To construct this object we need to provide
-
the finite element space
Vh -
the value
u_0of the solution at the Dirichlet boundary.u_0can either be aConstantor anExpressionobject. -
the object
Boundarythat defines on which part of $\partial \Omega$ we want to impose such condition.
f = Constant(1.)
k1 = Constant(0.05)
k2 = Constant(1.)
Pi = Constant(.5)*(k1 + k2*uh*uh)*inner(nabla_grad(uh), nabla_grad(uh))*dx - f*uh*dx
class Boundary(SubDomain):
def inside(self, x, on_boundary):
return on_boundary
u_0 = Constant(0.)
bc = DirichletBC(Vh,u_0, Boundary() )
4. First variation
The weak form of the first variation reads
We use a finite difference check to verify that our derivation is correct. More specifically, we consider a function
and we verify that for a random direction $\hat{u} \in H^1_0(\Omega)$ we have
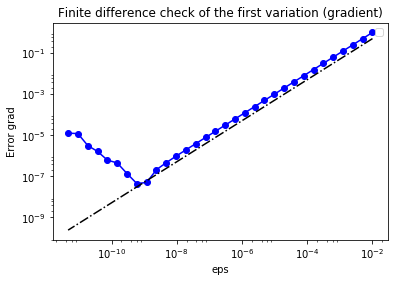
In the figure below we show in a loglog scale the value of $r$ as a function of $\varepsilon$. We observe that $r$ decays linearly for a wide range of values of $\varepsilon$, however we notice an increase in the error for extremely small values of $\varepsilon$ due to numerical stability and finite precision arithmetic.
NOTE: To compute the first variation we can also use the symbolic differentiation of variational forms capabilities of FEniCS and write
grad = derivative(Pi, u, u_hat)
grad = (k2*uh*u_hat)*inner(nabla_grad(uh), nabla_grad(uh))*dx + \
(k1 + k2*uh*uh)*inner(nabla_grad(uh), nabla_grad(u_hat))*dx - f*u_hat*dx
u0 = interpolate(Expression("x[0]*(x[0]-1)*x[1]*(x[1]-1)", degree=2), Vh)
n_eps = 32
eps = 1e-2*np.power(2., -np.arange(n_eps))
err_grad = np.zeros(n_eps)
uh.assign(u0)
pi0 = assemble(Pi)
grad0 = assemble(grad)
uhat = Function(Vh).vector()
uhat.set_local(np.random.randn(Vh.dim()))
uhat.apply("")
bc.apply(uhat)
dir_grad0 = grad0.inner(uhat)
for i in range(n_eps):
uh.assign(u0)
uh.vector().axpy(eps[i], uhat) #uh = uh + eps[i]*dir
piplus = assemble(Pi)
err_grad[i] = abs( (piplus - pi0)/eps[i] - dir_grad0 )
plt.figure()
plt.loglog(eps, err_grad, "-ob", label="Error Grad")
plt.loglog(eps, (.5*err_grad[0]/eps[0])*eps, "-.k", label="First Order")
plt.title("Finite difference check of the first variation (gradient)")
plt.xlabel("eps")
plt.ylabel("Error grad")
plt.legend(loc = "upper left")
5. Second variation
The weak form of the second variation reads
As before, we verify that for a random direction $\hat{u} \in H^1_0(\Omega)$ we have
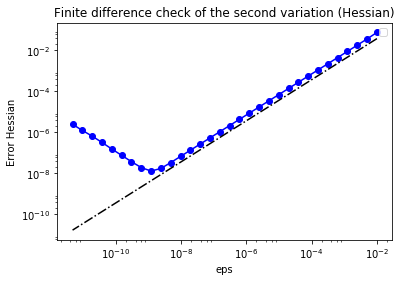
In the figure below we show in a loglog scale the value of $r$ as a function of $\varepsilon$. As before, we observe that $r$ decays linearly for a wide range of values of $\varepsilon$, however we notice an increase in the error for extremely small values of $\varepsilon$ due to numerical stability and finite precision arithmetic.
NOTE: To compute the second variation we can also use automatic differentiation and write
H = derivative(grad, u, u_tilde)
H = k2*u_tilde*u_hat*inner(nabla_grad(uh), nabla_grad(uh))*dx + \
Constant(2.)*(k2*uh*u_hat)*inner(nabla_grad(u_tilde), nabla_grad(uh))*dx + \
Constant(2.)*k2*u_tilde*uh*inner(nabla_grad(uh), nabla_grad(u_hat))*dx + \
(k1 + k2*uh*uh)*inner(nabla_grad(u_tilde), nabla_grad(u_hat))*dx
uh.assign(u0)
H_0 = assemble(H)
H_0uhat = H_0 * uhat
err_H = np.zeros(n_eps)
for i in range(n_eps):
uh.assign(u0)
uh.vector().axpy(eps[i], uhat)
grad_plus = assemble(grad)
diff_grad = (grad_plus - grad0)
diff_grad *= 1/eps[i]
err_H[i] = (diff_grad - H_0uhat).norm("l2")
plt.figure()
plt.loglog(eps, err_H, "-ob", label="Error Hessian")
plt.loglog(eps, (.5*err_H[0]/eps[0])*eps, "-.k", label="First Order")
plt.title("Finite difference check of the second variation (Hessian)")
plt.xlabel("eps")
plt.ylabel("Error Hessian")
plt.legend(loc = "upper left")
6. The infinite dimensional Newton Method
The infinite dimensional Newton step reads
Given $u_n \in H_0^1$, find $\tilde{u} \in H^1_0$ such that
Update the solution $u_{n+1}$ using the Newton direction $\tilde{u}$
Here, for simplicity, we choose $\alpha$ equal to 1. In general, to guarantee global convergence of the Newton method the parameter $\alpha$ should be appropriately chosen (e.g. back-tracking or line search).
The linear systems to compute the Newton directions are solved using the conjugate gradient (CG) with algebraic multigrid preconditioner with a fixed tolerance. In practice, one should solve the Newton system inexactly by early termination of CG iterations via Eisenstat–Walker (to prevent oversolving) and Steihaug (to avoid negative curvature) criteria.
In the output below, for each iteration we report the number of CG iterations, the value of the energy functional, the norm of the gradient, and the inner product between the gradient and the Newton direction $\delta_u \Pi(u_0, \tilde{u})$.
In the example, the stopping criterion is relative norm of the gradient $\frac{\delta_u \Pi(u_n, \hat{u})}{\delta_u \Pi(u_0, \hat{u})} \leq \tau$. However robust implementation of the stopping criterion should monitor also the quantity $\delta_u \Pi(u_0, \tilde{u})$.
uh.assign(interpolate(Constant(0.), Vh))
rtol = 1e-9
max_iter = 10
pi0 = assemble(Pi)
g0 = assemble(grad)
bc.apply(g0)
tol = g0.norm("l2")*rtol
du = Function(Vh).vector()
lin_it = 0
print "{0:3} {1:3} {2:15} {3:15} {4:15}".format(
"It", "cg_it", "Energy", "(g,du)", "||g||l2")
for i in range(max_iter):
[Hn, gn] = assemble_system(H, grad, bc)
if gn.norm("l2") < tol:
print "\nConverged in ", i, "Newton iterations and ", lin_it, "linear iterations."
break
myit = solve(Hn, du, gn, "cg", "petsc_amg")
lin_it = lin_it + myit
uh.vector().axpy(-1., du)
pi = assemble(Pi)
print "{0:3d} {1:3d} {2:15e} {3:15e} {4:15e}".format(
i, myit, pi, -gn.inner(du), gn.norm("l2"))
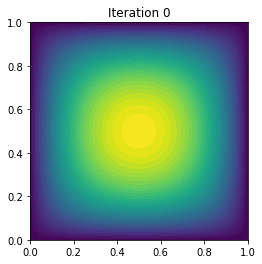
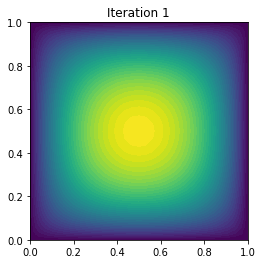
plt.figure()
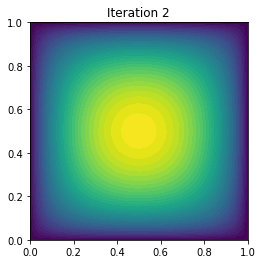
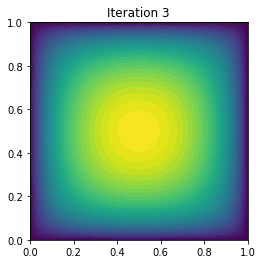
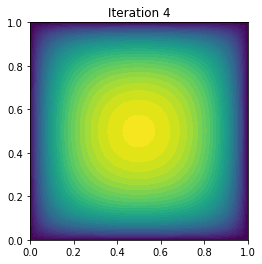
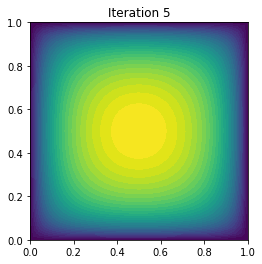
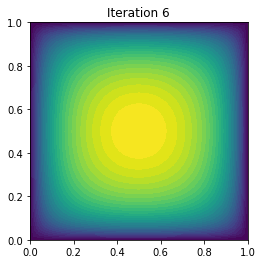
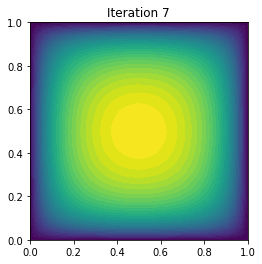
plot(uh, title="Iteration {0:1d}".format(i))
It cg_it Energy (g,du) ||g||l2
0 5 2.131676e+00 -7.006604e-01 3.027344e-02
1 4 1.970929e-01 -3.236479e+00 4.776446e-01
2 4 -1.353237e-01 -5.650320e-01 1.383324e-01
3 4 -1.773194e-01 -7.431321e-02 3.724057e-02
4 4 -1.796716e-01 -4.455252e-03 7.765393e-03
5 4 -1.796910e-01 -3.850147e-05 7.391932e-04
6 4 -1.796910e-01 -4.634514e-09 9.311078e-06
7 4 -1.796910e-01 -8.722540e-17 1.526855e-09
Converged in 8 Newton iterations and 33 linear iterations.
7. The built-in non-linear solver in FEniCS
As an alternative, we can resort to the built-in non-linear solver in FEniCS.
To this aim, we use the necessary optimality condition and we cast the minimization problem in a non-linear variational problem. More specifically, we set first variation $\delta_u \Pi(u,\hat{u})$ of the energy functional to zero.
The input to the solve functions are
-
the weak form of the residual equation (i.e. the first variation $\delta_u \Pi(u,\hat{u})$ of the energy functional);
-
the initial guess (INPUT)/solution (OUTPUT) of the non-linear problem;
-
the Dirichlet boundary conditions;
-
the Jacobian of the residual equation (i.e. the second variation $\delta_u^2 \Pi(u,\hat{u}, \tilde{u})$ of the energy functional). If the Jacobian form is not provided, FEniCS will compute it by automatic differentiation of the residual weak form;
-
additional parameters for the linear and non-linear solver.
uh.assign(interpolate(Constant(0.), Vh))
parameters={"symmetric": True, "newton_solver": {"relative_tolerance": 1e-9, "report": True, \
"linear_solver": "cg", "preconditioner": "petsc_amg"}}
solve(grad == 0, uh, bc, J=H, solver_parameters=parameters)
final_g = assemble(grad)
bc.apply(final_g)
print "Norm of the gradient at converge", final_g.norm("l2")
print "Value of the energy functional at convergence", assemble(Pi)
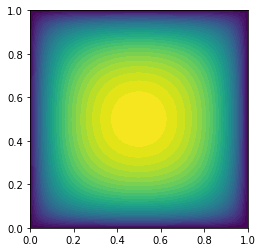
plot(uh)
Norm of the gradient at converge 4.29367270883e-14
Value of the energy functional at convergence -0.179690966184
Copyright (c) 2016, The University of Texas at Austin & University of California, Merced. All Rights reserved. See file COPYRIGHT for details.
This file is part of the hIPPYlib library. For more information and source code availability see https://hippylib.github.io.
hIPPYlib is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License (as published by the Free Software Foundation) version 2.0 dated June 1991.